Search, Navigation, and Code Completion
IDE Development Course
Andrew Vasilyev
Licensed under CC BY-NC-SA 4.0
Lecture Agenda
- Solutiod-wide Analysis
- Code Navigation
- "Find Usages" Feature
- Code Completion
- Refactorings and Quick Fixes
- Code Generation
Solution-wide Analysis
Solution-wide Analysis

Solution-wide analysis is a comprehensive process within IDEs that performs an extensive scan of all the files in a software solution. This technique detects errors, warnings, and potential improvements across the entire project scope, ensuring a higher level of code quality and adherence to best practices.
How to Implement?
- Run in Background in Multiple Threads: Utilize parallel computing to perform the analysis without blocking the main IDE operations, enhancing performance and responsiveness.
- Fine-Grained File Locks: Implement a locking mechanism that minimizes conflicts and interference with ongoing development activities while ensuring data integrity during analysis.
- Make It Iterative: Design the analysis process to be iterative, allowing incremental updates and minimizing the need for full project scans with each change.
- Reanalyze Only Changed and Dependent Files: Develop a dependency graph to track file relationships and limit reanalysis to only those files and their dependencies affected by recent changes.
Code Navigation
Code Navigation
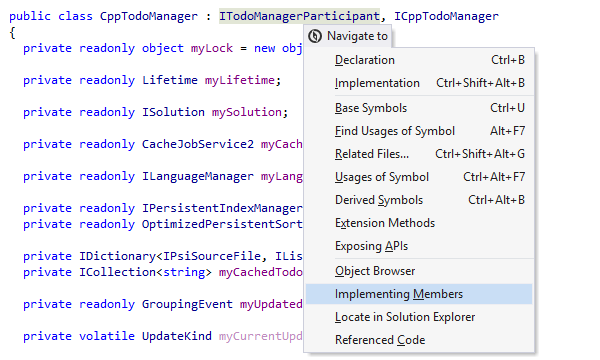
Code Navigation in an IDE is a sophisticated set of features that facilitates seamless movement across various components of a software project. It enables developers to efficiently locate, view, and modify code segments within extensive codebases, enhancing overall productivity and code comprehension.
Code Navigation - Go To Declaration
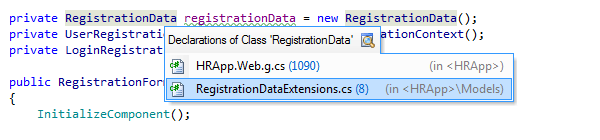
'Go To Declaration' is a pivotal feature in modern IDEs that allows developers to instantly navigate to the source declaration of any symbol in the code. This quick jump is instrumental in understanding the underlying properties, definitions, and configurations of variables, methods, classes, or interfaces.
Code Navigation - Go To Symbol
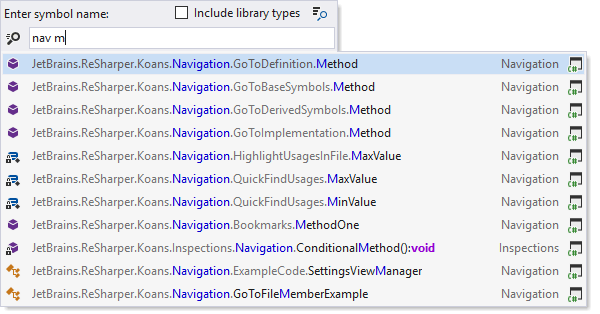
'Go To Symbol' empowers developers to directly access any specific symbol in the codebase. It bypasses the need for manual searching, allowing quick navigation to functions, variables, classes, or any other code elements, significantly streamlining the development process.
Code Navigation - Go To File Member
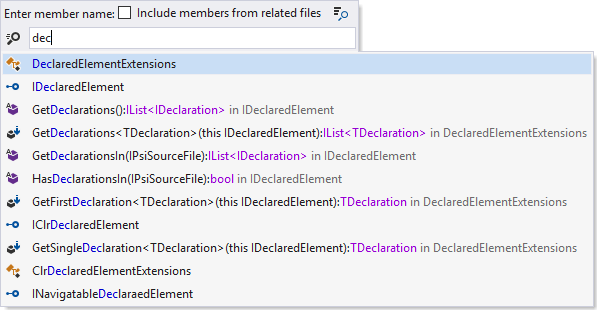
'Go To File Member' is a navigation feature focused on finding and accessing specific members within a file, such as methods, fields, or properties. This feature is invaluable in navigating large files and understanding the structure and components of the code at a glance.
Implementing Code Navigation
- Resolve Reference if Needed: Analyze the code to resolve references, guiding navigation towards the correct declaration or symbol.
- Determine Context: Ascertain the current context within the IDE to offer contextually relevant navigation options.
- Determine Search Domain: Specify the scope of the navigation search, be it a specific file, project, or across the entire codebase.
- Traverse Symbol Tables: Navigate through symbol tables efficiently to locate the requested navigation target.
- Build a List of Variants: Compile a comprehensive list of potential navigation destinations based on the search query and context.
- Offer User Selection of Variants: Present the user with a choice of navigation options, allowing them to select the most relevant destination.
"Find Usages" Feature

The "Find Usages" feature is a crucial tool in IDEs that empowers developers to pinpoint every instance where a specific symbol, like a variable, method, or class, is utilized in the codebase. This functionality is pivotal for assessing the ramifications of code modifications, aiding in effective refactoring, and ensuring code integrity.
Implementing "Find Usages"
- Determine Context and Domain: Identify the current coding environment and the scope of the analysis, considering factors such as programming language and project-specific characteristics.
- Scan Project and Resolve References: Conduct a comprehensive scan of the project, resolving all code references to ensure accurate identification of symbol usage.
- Traverse Symbol Tables and Collect Occurrences: Methodically navigate through symbol tables, gathering instances of the symbol's occurrences for a thorough analysis.
- Prebuild Symbol Index if Solution-Wide Error Analysis (SWEA) is Available: Leverage SWEA to construct an index of symbols, which accelerates the "Find Usages" process and enhances accuracy.
Challenges
- Handling Large Codebases: Managing the complexity and scale of extensive projects.
- Accurate Symbol Resolution: Ensuring precise identification of symbols amidst various scopes and declarations in complex code environments.
- Maintaining Context Relevance: Providing results that are relevant to the developer's current context and do not overwhelm with unnecessary data.
- Performance Optimization: Balancing thoroughness of search with the need for speed, ensuring that the feature does not hinder the overall performance of the IDE.
Code Completion
Code Completion
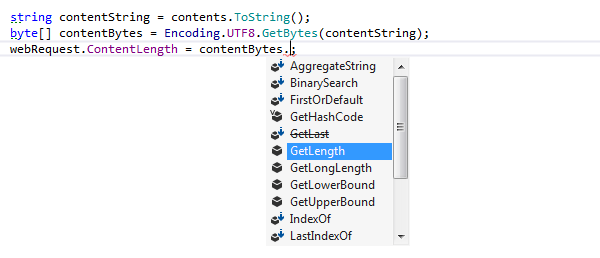
Code Completion in IDEs is an advanced feature designed to enhance coding efficiency by predicting and suggesting possible code fragments based on the current context. It significantly speeds up the coding process by reducing typing effort and helps in avoiding syntax and typographical errors.
How to implement?
- Determine Qualifier and Context: Identify the current coding context and the qualifier from which suggestions will be generated.
- Traverse Symbol Tables and Collect Variants: Methodically navigate through symbol tables to gather possible code completions.
- Prioritize Variants: Organize the collected variants in a logical order, prioritizing the most relevant suggestions based on context.
- Offer User to Select: Display a sorted list of suggestions to the user, allowing them to choose the most appropriate completion.
Prioritization Techniques
- Frequency of Use: Prioritize suggestions based on the frequency of their usage in the codebase.
- Contextual Relevance: Rank suggestions higher if they are more relevant to the current coding context.
- Lexical Proximity: Give preference to symbols that are lexically closer to the point of completion.
- Historical User Preference: Adapt suggestions based on the historical preferences and patterns of the developer.
- Typing Pattern Recognition: Utilize intelligent algorithms to predict likely completions based on the developer's typing patterns.
Code Generation and Modification
Code Generation
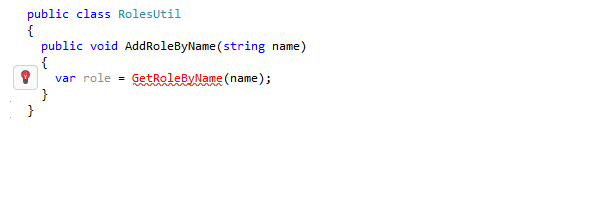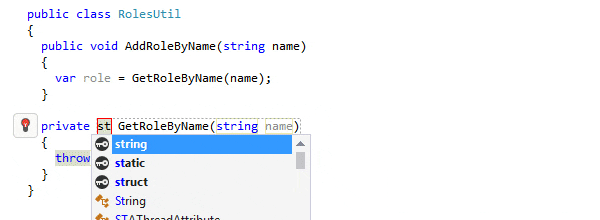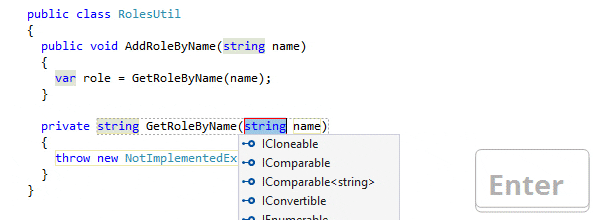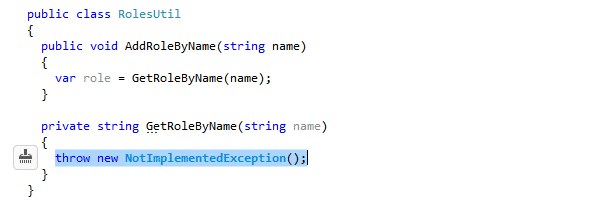
Code generation in IDEs automates the creation of code snippets and structures, significantly reducing manual coding effort. It enhances productivity by generating reliable, pattern-based code for common programming tasks, like setting up boilerplate code, implementing patterns, or creating CRUD operations. This feature is especially useful in large projects where consistency and adherence to design patterns are crucial.
Refactorings
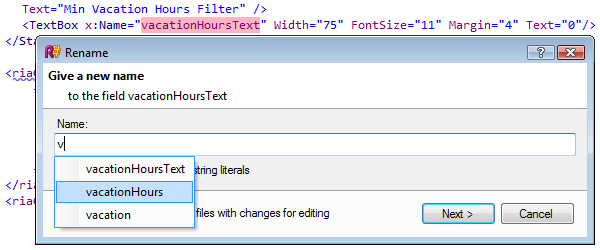
Refactoring is the process of restructuring existing computer code without changing its external behavior. It's a vital aspect of software maintenance and evolution, aimed at improving the non-functional attributes of the code. Common refactoring activities include renaming variables for clarity, breaking down large functions into smaller ones, and reorganizing code for better readability and maintainability. IDEs assist in refactoring by automating these tasks and ensuring that changes do not affect the program's functionality.
Quickfixes and Context Actions
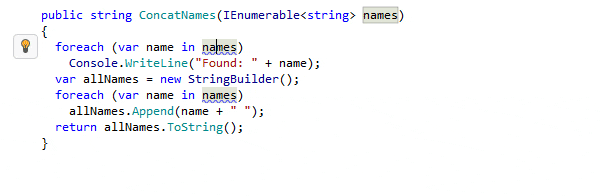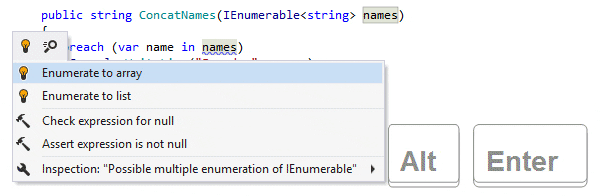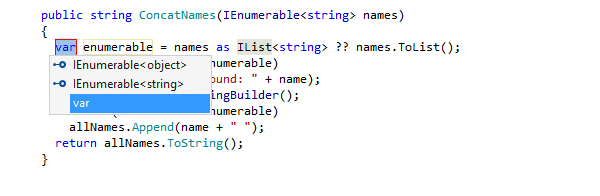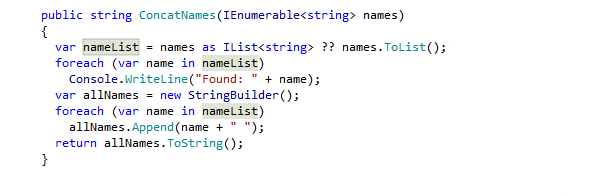
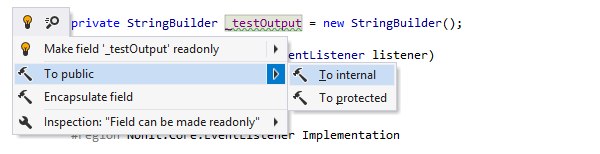
Quickfixes in IDEs are automated solutions offered to resolve detected code issues, like syntax errors or potential bugs. They provide immediate and context-sensitive corrections that improve code quality and adherence to best practices. Context Actions, on the other hand, are proactive suggestions not necessarily tied to code problems but aimed at enhancing code readability, structure, or performance. Unlike Quickfixes, which are often essential for code correctness, Context Actions offer optional, yet beneficial, transformations and refactorings to improve the overall quality and maintainability of the code.
How to Implement?
- Analyze PSI: Examine PSI to understand the current code structure and identify what should be done.
- Modify/Create PSI: Based on the refactoring needs, modify existing PSI elements or create new ones to represent the desired changes.
- Validate Updated PSI: Ensure that the changes made to the PSI are valid and do not break the code structure or logic.
- Fix Issues: Address any issues or inconsistencies identified during the PSI validation step.
- Materialize Updated PSI Nodes: Convert the modified or newly created PSI elements into actual code changes.
- Replace Old Code with New: Apply the final changes to the codebase by replacing the old code with the newly generated code, ensuring a seamless transition and maintaining code integrity.
How to Implement?
- Modification: Utilize the UnitOfWork pattern or PSI transactions for safe and atomic code modifications. This approach allows for grouping a series of changes into a single operation, ensuring consistency and enabling easier rollback if needed.
- Validation: Conduct thorough checks for name conflicts, correct usage of variables and methods, and proper module imports. This step is crucial to avoid introducing errors into the codebase and to ensure that the refactoring aligns with the existing code architecture and dependencies.
- Materialization: Traverse the PSI nodes in-depth to generate new code segments. Carefully replace the old code with the new, ensuring that the new code integrates seamlessly with the rest of the project. This process involves not just the physical replacement of code but also the preservation of code formatting, comments, and other non-functional elements.
Challenges
- Behavioral Preservation: Ensuring that the refactored code maintains the same external behavior and functionality as the original.
- Consistency: Achieving consistency in both code structure and design patterns across the entire codebase. Refactoring should unify disparate coding practices to ensure uniformity, which is especially challenging in large or legacy codebases with varied coding styles and practices.
- Bulk Updates: Managing bulk updates efficiently while ensuring accuracy and consistency is a significant challenge. It involves updating large portions of the codebase simultaneously, which can introduce risks of mass errors or inconsistencies if not managed carefully.
Challenges
- Code Style: Maintaining a consistent code style during refactoring is crucial for readability and maintainability. Refactoring should adhere to the project's coding standards and style guides to ensure that the new code fits seamlessly with the existing codebase.
- Comments: Preserving and updating comments during refactoring is essential to keep the code well-documented. However, it is challenging to update comments automatically to reflect changes in the code, often requiring manual review and adjustments.
Example: "Rename" Refactoring
- Identify Rename Scope: Analyze the codebase to determine the variables, methods, classes, or files to be renamed. This step includes identifying all references to these elements throughout the project to ensure a comprehensive renaming.
- Symbol Resolution: Use symbol resolution techniques to accurately identify and distinguish all instances of the symbol. This ensures that only relevant references are affected by the rename operation, avoiding unintentional changes to unrelated code.
- Conflict Detection: Scan for potential naming conflicts or ambiguities that might arise from the renaming. This involves checking against existing names in the scope and considering language-specific naming rules.
Example: "Rename" Refactoring
- User Input and Preview: Engage the user in the process by allowing them to input the new name and providing a preview of the changes. This step includes showing the impact of the rename operation on various parts of the codebase.
- Refactoring Execution: Execute the renaming process across the entire PSI, ensuring that all identified references are updated consistently and correctly, thereby maintaining the integrity of the codebase.
- Materialize Changes: Reflect the changes made in the PSI in the project files. This includes updating the code files, any related documentation, and ensuring that the changes persist across the development environment.
Conclusion
Even More Features
- Typing Assistance: Tools that aid in reducing typing effort and errors, such as auto-indentation and brace matching.
- Full Text Search: A feature that allows developers to search across the entire codebase for specific text strings.
- Semantic Search: Advanced search functionality that understands the context and semantics of the code, beyond mere text matching.
- Fuzzy and Typing-Errors-Proof Search: Search capabilities that can tolerate and correct typing errors, offering relevant results despite inaccuracies.
Even More Features
- Code Hierarchies and Diagrams: Tools for visualizing code structures and relationships through hierarchies and diagrams, aiding in understanding complex codebases.
- Code Style and Cleanup: Features that help in maintaining a consistent coding style and automatically cleaning up code to meet predefined standards.
- Unit-Testing Assistance: Integrated tools that support the creation, execution, and management of unit tests, streamlining the testing process.
Next: Artificial Intelligence and the Future of IDEs
Explore how Artificial Intelligence (AI) is shaping the future of Integrated Development Environments (IDEs), transforming them into more intelligent, efficient, and intuitive tools. Discuss the potential of AI in code analysis, automated refactoring, predictive coding, and personalized developer assistance, and how these advancements could revolutionize software development processes.
Questions & Answers
Thank you for your attention!
I'm now open to any questions you might have.